Random Forest e o Akinator da vida adulta (pt.1)
- Vinicius Araujo
- 5 de jun. de 2024
- 5 min de leitura
A inteligência artificial (IA) é o assunto do momento e você já deve estar cansando de saber. A prova direta disso é que atualmente só existem dois tipos de pessoas:
As que já fizeram perguntas de caráter duvidoso no chatGPT; e
As que ainda não tinham pensado nisso e devem estar indo lá agora mesmo fazer (recomendado pelo autor).
Brincadeiras e chatGPT à parte, é cada vez mais comum encontrar "Alexas" dentro de nossas casas ou receber aquela velha e chata recomendação do produto (exatamente aquele) que você nem mesmo se lembrava de ter dito em voz alta que queria, mas que o Google já estava te mostrando algumas opções.
Poucos sabem que, na verdade, essa história já vem de tempos e que até alguns joguinhos antigos que você provavelmente jogou em sua adolescência já bebiam da fonte da inteligência artificial.
Tenho me aventurado em projetos de IA nos últimos tempos e resolvi reunir alguns conceitos essenciais de Random Forest para (tentar) te explicar de maneira simplificada o funcionamento de um dos algoritmos de machine learning mais queridinhos do pessoal de Dados.
A ideia basica por trás do algoritmo
O Random Forest, ou a Floresta Aleatória (nunca vi ninguém chamar da forma traduzida juro, kk) é um algoritmo de machine learning supervisionado, amplamente implementado pela comunidade de dados e que pode ser utilizado para tarefas de classificação e de regressão. Muita coisa estranha logo no primeiro parágrafo, eu sei, mas vamos detalhar mais cada uma delas abaixo:
Supervisionado vem do fato de que esse tipo de abordagem utiliza conjuntos de dados rotulados para o treinamento do algoritmo, ou seja, você precisa previamente mostrar ao algoritmo o que é certo e o que é errado para que as predições possam ser realizadas (sim, nem todos os algoritmos necessitam aprender com exemplos prévios, tipo os de Clusterização de Dados, que faleremos num próximo artigo).
As tarefas de classificação são aquelas que retornam categorias como “Gosta [de carros]” ou “Não gosta [de carros]” e as tarefas de regressão são aquelas que retornam um valor numérico, como para a pergunta “Qual o valor de um aluguel de um apartamento de 72m² em São Paulo?”.
Esse tipo de algoritmo é amplamente utilizado pela comunidade de dados pela praticidade de implementação e por ser mais facilmente interpretável, fugindo de algumas abordagens chamadas “caixa-preta”, onde não se sabe exatamente o que foi feito para que a predição acontecesse.
De maneira simples e direta e focando aqui na tarefa de classificação, o algortimo se baseia num conjunto de perguntas e respostas para ganhar informações privilegiadas e ficar confiante o suficiente para poder arriscar um palpite sobre uma certa categoria. Parece familiar? Quem aqui se lembra do Akinator?

O Akinator da vida adulta e a experiência de um cliente
O Akinator é um jogo de adivinhação de personagens que foi muito famoso no Brasil em 2009 e funcionava de maneira simples: você pensava secretamente em um personagem e respondia a uma série de perguntas (aparentemente muito abertas) feitas pelo gênio da lâmpada e, após poucas interações, ele adivinhava (com uma precisão surpreendente) qual era o nome do personagem que você tinha pensado (!!!).
Não conhecemos todos os segredos por trás do Akinator, mas vamos utilizar uma versão simplificada nesse contexto de perguntas e respostas para exemplificar de uma forma um poquinho mais didática o algoritmo de Random Forest. Imagine que queiramos antecipar se “um cliente da nossa empresa Lampadas Inc dirá ter uma experiência ruim com o nosso aplicativo de compras na pesquisa de satisfação”. As seguintes perguntas foram feitas para o gênio:
O cliente fez alguma compra pelo aplicativo nos ultimos 3 meses?
O cliente precisou falar com o suporte para tirar alguma dúvida?
De maneira mais visual, poderíamos representar o nosso público-alvo com a visualização abaixo, onde os pontos em vermelho são o nosso objetivo, ou seja, clientes que disseram ter uma experiência ruim na última pesquisa de satisfação enviada para eles, e os em azul, clientes que disseram ter uma experiência boa.

Cada uma das bolinhas carrega um contexto, um conjunto de variáveis que temos nas nossas bases de dados e que representam de alguma maneira o histórico desses clientes na companhia. A idea por trás de se fazer perguntas específicas para o gênio se traduz no feito de reduzir esse espaço de possibilidades (ser ou não ser um cliente com experiencia ruim, eis a questão), separando bolinhas através de suas próprias características. Ilustramos a separação pelo comportamento de compras dos clientes nos ultimos três meses com a imagem abaixo:

A primeira pergunta feita parece ter separado bem os clientes, pois apenas dois pontos vermelhos se mantiveram no lado esquerdo (não fizeram compras) enquanto que a maior parte deles se manteve no lado direito (fizeram compras).
Queremos utilizar essa informação para que quando um cliente no futuro repita esse comportamento (não fazer compras por um período de 3 meses), podermos predizer que ele provavelmente dirá ter uma experiência ruim antes que ele responda a pesquisa de satisfação. E nesse caso, poderíamos tentar corrigir essa experiência de alguma maneira antes dessa resposta. Mas só com essa pergunta ainda teríamos pouco conhecimento, temos mais oportunidades de recorte no lado direito, por conta disso faremos a segunda pergunta:

Agora sim! Visualmente já se nota uma parte mais concetrada de bolinhas vermelhas no canto superior direito! De maneira mais formal, algoritmos baseados em árvores separam o hiperplano dos dados em segmentos de reta a fim de se encontrar essas regiões onde as classes (experiencia ruim ou não) estejam mais concentradas, ajudando-nos a formar uma opinião. Techniquês a parte, com a concentração encontrada acima, já teríamos mais confiança para dizer que clientes que fazem compras mas que tiveram que tirar dúvidas com o suporte têm geralmente uma experiência ruim com o aplicativo.
Uma forma também interessante de se visualizar esses algoritmos é através de um diagrama de árvore (por isso o nome do método). Nele, a primeira pergunta pode ser interpretada como a raiz, as perguntas seguintes seriam os ramos (ou galhos, ou nós) e a decisão final tomada no final de um trajeto seria tomada na folha:
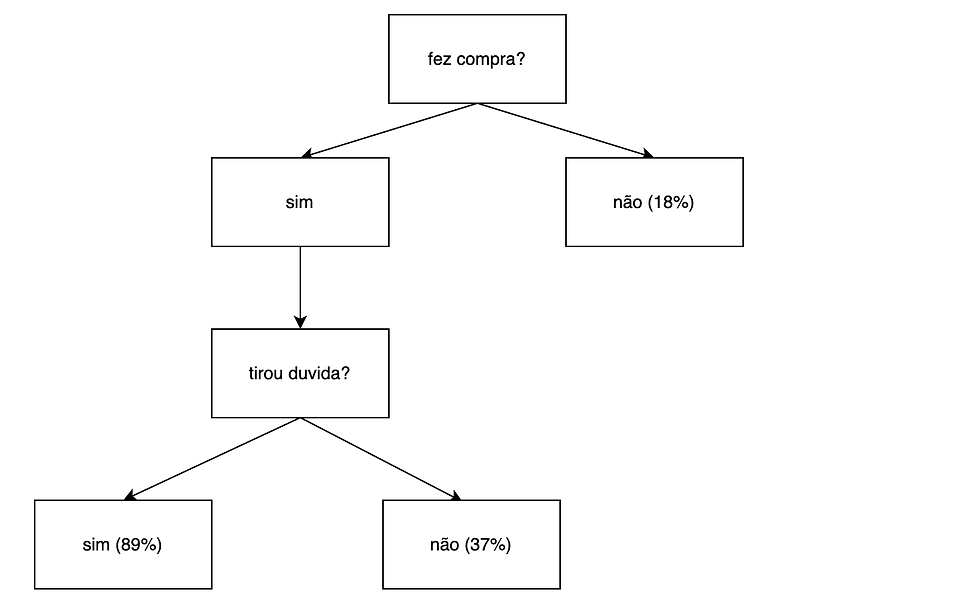
A medida que vamos fazendo mais perguntas, ganhamos mais informação a respeito do nosso público e, fazendo uma contagem simples das bolinhas, notamos que, dos clientes que fizeram compras nos últimos 3 meses e que também tiraram alguma dúvida com o suporte, 89% deles tiveram uma experiência ruim com a nossa empresa. Em contrapartida, os clientes que fizeram compras e não tiraram dúvidas tem um percentual menor de 37% de insatisfação.
Esse percentual mencionado acima é uma proxy (aproximação) para a confiança do gênio da lampada, e essa categoria mais frequente seria a aposta dele para um cliente que se enquadrasse nesse cenário. Decidir qual nível de confiança (ou threshold) é o suficiente para se tomar uma decisão é uma ciência, uma espécie de refinamento do modelo que abordaremos em outro momento.
Fazer perguntas é bom, mas afulinar demais o problema nem sempre é aconselhável. Muitas divisões no dado tornam o processo de descoberta mais lento, computacionalmente mais complexo, custoso e, além disso, específico demais. Nesses casos, o modelo se adapta demais aos dados fornecidos no presente, “decorando” os caminhos existentes, mas ele se confundiria com informações que fugissem desse padrão no futuro (overfitting).
Quantas perguntas devemos fazer, então? A ordem delas importa? Como saber se uma pergunta feita é boa? Para responder a essas e outras questões precisamos nos perguntar quanto de informação estamos ganhando com cada uma das perguntas e o próximo artigo dessa série abordará um pouco mais desse conceito.
Até o próximo!
Comments